![]() Biology C2005 Lecture 4
Biology C2005 Lecture 4
Unlike the catch-all category of LIPIDS, NUCLEIC
ACIDS are biopolymers par excellence. There are 2 types, DNA and
RNA, the monomers are nucleotides, that have nitrogen-containing rings
and 5-carbon sugars. There are four types of monomers in each polymer.
We will discuss them in detail, but not for a few weeks yet.
::Proteins: Amino
acids are the monomers (20)::
PROTEINS. These are the
most important class of macromolecules in the cell, and we will discuss
them now in detail. The monomers that make up proteins are the amino acids,
of which there are 20. The same 20 in E. coli and in elephants and in
tomatoes.
The general structure of an amino acid is:
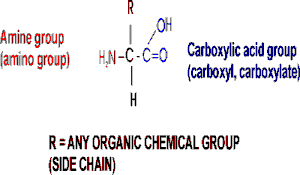
Note the central carbon atom, to which 4 different groups are attached:
an amino group (drawn by convention at the left), a carboxylic acid group
(put at the right side), a hydrogen, and a side chain, or R-group. Only
the R-group varies among the 20 different amino acids. This is the side
chain, and so there are 20 different side chains. Look at the amino
acids and peptides handout for some of the side chains. Your texts
and hard copy handout show al l 20, and you should examine all 20.
Out of laziness, I drew the general amino acid incorrectly:
Actually at neutral pH, the molecule is charged, because the carboxylic
acid group is an acid, and the amine group is a base, so more accurately:
(also see 3-D
picture)
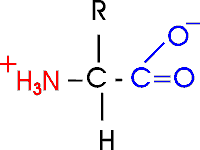
Let's take this opportunity to discuss the charge
on organic molecules a bit more. In living systems, the carboxylic acid
group is mostly charged and the amine is mostly charged, but that is a
pH7, the cellular pH under most circumstances. Is an acid always charged
in aqueous solution? No. It depends on the pH of the environment. In the
laboratory we do not have to keep things at pH 7, as it is in the cell.
We can vary the environment at will, adding strong acids such as hydrochloric
acid as a source of hydrogen ions (lowering the pH), or a strong base
such as sodium hydroxide (raising the pH). The strength of an acid is
a measure of how readily it gives up a proton. Carboxylic acids are always
in equilibrium with the hydrogen ions (protons) in the solution, so if
the hydrogen ion concentration is high (acidic) then the equilibrium will
shift toward the protonated (uncharged) species. At pH 3 an amino acid
carboxyl group is protonated about half the time; for each pH unit this
proportion of protonated species will drop by a factor of 10, so very
little of the carboxyl group is protonated at the neutral pH of 7 found
in most cells. A similar situation pertains to the amine base end: at
a very low H+ ion concentration (e.g., 10-11M H+, a high pH of 11), it
will tend to lose its extra proton, but at pH y,it will mostly remain
protonated, with a positive charge. ly. high pH .
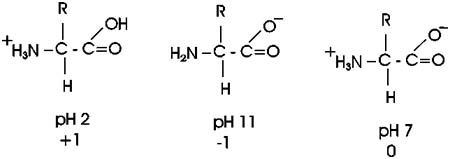
So at pH7, most amino acids are neutral (no net charge), but they are
highly charged nonetheless.
Now, what are some of these 20 different side groups?
Here are 2 charged side group, e.g.:
asp: R= -CH2-COO- , there is a second carboxyl group on this amino acid)
lys: R= -CH2-CH2-CH2-CH2-NH3+ , there's a second amine on lysine, so lysine
will have 3 charged groups, and a net charge of +1 (two +'s and one -)
at pH7.
There is a convention for numbering amino acid carbons; actually
it's a lettering. It starts from the central carbon, called alpha: so
lys has (count with me) an alpha, beta, gamma, delta, EPSILON-amino group
as well as an alpha-amino group (and an alpha-carboxyl).
The average molecular weight of an aminoacid is ~120,but the range is
from 75 to 203.
The smallest amino acid (a.a.) is glycine (gly), MW = 75. Here the side
chain is merely hydrogen.
The largest is tryptophan (trp), MW = 203 [-CH2- bridge to a 5-membered
ring containing a N + a fused 6-membered ring] and fairly hydrophobic.
Look over the structures of the 20 amino acids in the textbook. It is
the properties of the functional groups on
the 20 different side chains of the 20 different
amino acids that determine the function of a protein, so they are all-important.
The handout shows all 20 aa's, but without indicating the ionization of
the acidic and basic groups. We will discuss many of the side chains within
the context of the discussion as we go along.
There are a couple that deserve special mention: arginine contains a functional
group that is not on your list; it is -NH-CH2(NH2)NH2, called the guanido
group. The guanido group is a strong base, even stronger than an ordinary
amine, so it is positively charged at pH7 (like lysine). Proline has a
side chain that folds back and forms a covalent bond to the amine nitrogen
of the amino acid, thus producing a ring structure.
You should be able to recognize the properties of the side chains as polar
or non-polar, charged or not charged. You will not be responsible for
recalling a specific amino acid structure from the English name or vice
versa, but given the structure you should know how it behaves. {Q&A}.
::Stereoisomers::
Now let's consider the structure of an amino acid
in 3 dimensions:
When carbon forms 4 single bonds, it makes them spaced equally apart from
each other in space, in the form of a tetrahedron as in this representation
of glycine [a model with 2 white groups is shown].
Now consider this other molecule of an amino acid [again with 2 white
groups], with 2 H's of glycine, e.g. Are these the same molecule, that
is, are they distinguishable or are they indistinguishable?
They are indistinguishable, since I can rotate them and superimpose their
atoms.
But now suppose I make this alanine instead of glycine. I replace one
H with a [blue] -CH3 group on each molecule [I am being sure to make them
stereoisomers].
I can no longer superimpose them. They are both alanine, as they have
the same four groups attached to the central carbon. But in three dimensions
they are actually mirror images of each other. See [Purves6ed
2.21a]. We call one D-ala and one L-ala. See [Purves6ed
2.21b].
This one is D, or is it this one... ? I can't remember .. it's not too
important here.
What is important is that in general, you have this situation, the possibility
of two stereoisomers, whenever there is what
is called an ASYMMETRIC carbon atom in a molecule,
that is, a carbon with four different groups attached.
These stereo isomers are sometimes called optical
isomers, since the two forms, in solution, will bend a beam of polarized
light one way or the other. Thus the D designation originally meant dextro,
or to the right), whereas L stood for levo, to the left.
All amino acids except glycine have an asymmetric carbon, which is the
alpha-carbon. So we can draw 19 of the amino acids in 2 stereoisomeric
forms.
So do we really have 39 a.a.'s? No. All the stereoisomeric forms of the
amino acids in proteins are L-amino acids,
so we only have to worry about 20.
Note that the sugars we discussed, like glucose, have several asymmetric
carbon atoms. Aside from L and D designations, the sugar stereoisomers
are given different English names (e.g., D-glucose, D-mannose, L-rhamnose,
etc.).
::Polypeptides, peptide
bond:: Polymerization of aa's
OK, now let's string these L-amino acids together,
polymerize them. The bond that connects two amino acids is an AMIDE
bond (-CO-NH-) between the carboxyl of one amino acid and the amino group
of the next. Once again, a molecule of water is removed in the formation
of the connecting bond:

In the special case of proteins, this amide bond is called a PEPTIDE
BOND, and the resulting product a PEPTIDE,
a dipeptide (or we could go on to a tri-peptide, oligo-peptide, or finally,
POLY-PEPTIDE). (See also polypeptide
handout). Also see [Purves6ed
3.4], and another picture.
By convention, the amino group is written on the left for an amino acid
and also for a peptide.
In the tripeptide in the diagram, note the peptide bond (boxed), and the
repeating unit, or aa "residue" [circled]. Residue refers to what's left
of the amino acid monomer after it ahs been incorporated into a polypeptide,
which is most of it: it just lacks one H at what was the amino end and
one OH at what used to be the carboxyl end. Note also that the charged
amine and carboxyl groups no longer exist inside the polypeptide, having
been replaced by the amide, an uncharged functional group.
Almost all polypeptides have 2 ends, the amino
end and the carboxyl end, which do
remain charged at pH7. .
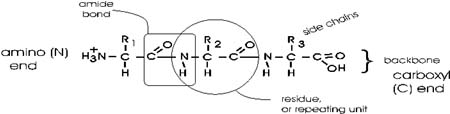
The "backbone" of the polypeptide is defined
as all of the atoms except the side chains.
The only free amino and carboxyl atoms of
the backbone are at the 2 ends.
The side chains then, stick out of this backbone (also see polypeptide
handout).
The length of polypeptides is commonly 100-1000 amino acids, but smaller
and larger ones also can be found.
Each and every protein molecule in the cell has an identity defined by
its particular sequence of amino acids. Each E. coli cell contains about
3 million polypeptide molecules, but only about 3000 different ones. Each
of these individual protein types has a name to go along with its chemical
identity.
Some examples of polypeptides, taken not from E. coli, but from more familiar
organisms include:
hemoglobin, which carries oxygen in red blood cells;
egg albumin, a nutrient in the white of a hen's egg;
keratin, providing toughness in skin, fingernails, and wool;
collagen, providing a strong connection between cells in tendons;
beta-galactosidase, which helps digest the milk sugar lactose.
::Primary (1o)=
linear sequences of AAs::
Each of these proteins contains a polypeptide with
a particular sequence of amino acids, usually all 20 are represented,
although not at all equally. Unlike polysaccharides, this sequence usually
exhibits no obvious regularity, or repeating subsequence:
This linear sequence
of amino acids is called the primary (1o)
structure of a protein.
::Methods: Paper
chromatography, electrophoresis, fingerprinting::
I will discuss a bit now some methodology
used in the purification of amino acids and proteins. We bring in some
selected lab methods from time to time for two reasons: First, the behavior
of molecules in experimental situations helps you to understand their
behavior in nature; and second, the methodology is interesting in its
own right as an example of how science is done.
Our first topic of methodology is directed at the question of how we get
to know this primary structure, this sequence of amino acids in a polypeptide?
One way to determine the sequence of a polypeptide is to chemically degrade
it in a stepwise fashion, starting at the carboxyl end. First you must
purify the polypeptide in question away from the other 3000 polypeptides
in the cell; we will discuss that process a little later.
The degradation of the polypeptide back to its
free monomer aa's is a form of HYDROLYSIS, a reverse of the dehydration
that accompanied the formation of the peptide bond. The controlled hydrolysis
of amino acid residues from the carboxyl end of a polypeptide is a form
of enzymatic hydrolysis; an enzyme, called carboxypeptidase, itself a
polypeptide, catalyzes this hydrolysis; it does not happen by itself.
We will learn more about enzymes next week. After the carboxypeptidase
is mixed with a peptide, hydrolysis begins: all the trillions of molecules
release their C-terminal amino acid in unison, synchronously, so that
in the first wave the last (original c-terminal) amino acid is released.
If the reaction is stopped at this point and the released amino acid is
separated from the main peptide and identified. By letting the reaction
proceed for increasing amounts of time, the time that amino acids are
released can be correlated with their distance form the C-terminal end.
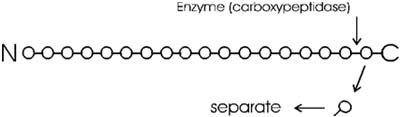

You can get the sequence of perhaps 20 amino acids from the carboxyl terminal
in this way, before the process breaks down. Since most polypeptides are
greater than 20 amino acids in length, you first need to chop the polypeptide
into manageable pieces and then sequence each piece by subjecting it to
hydrolysis by carboxypeptidase. Here I want to concentrate on the chemical
analysis problem of separating and identifying the different amino acids
that are released by this carboxypeptidase hydrolysis.
How do you know which amino acid came off when?
Amino acids will behave sufficiently differently from each other under
certain conditions to allow the complete separation of all 20 species
from a mixture. We will discuss two methods for separation and identification
here. One way is based on the migration of amino acids in an electric
field. In PAPER ELECTROPHORESIS, an amino acid mixture is spotted onto
a sheet of filter paper, the paper is wet with a buffer salt solution
and placed between two electrodes and a high voltage (e.g., 2000 volts)
applied. At neutral pH, the acidic amino acids (asp and glu) will have
a net negative charge and will migrate toward the ANODE (+ pole) while
the basic amino acids (arg and lys) will migrate toward the CATHODE (-
pole). {Q&A}
Electrically neutral amino acids will not migrate much, unless the pH
is made acidic or basic.
A more versatile separation method is PAPER CHROMATOGRAPHY. This method
is based on the differential solubility of the different amino acids
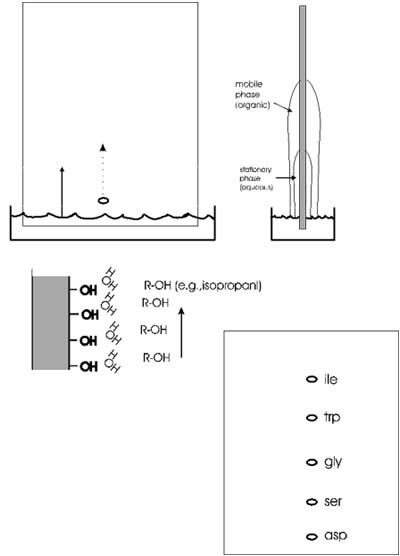
in organic (non-polar) solvents, which in turn
is determined by the nature of the side group. The amino acid mixture
is spotted onto a filter paper; one edge of the paper is immersed in a
mixture of aqueous and non-aqueous solvents. The liquid will be drawn
up the paper by capillary action. As it rises the water in the liquid
mixture is bound by the paper (cellulose, with its many OH groups), forming
a stationary water layer, or stationary phase. The organic solvent (e.g.,
propanol) moves up without as much interaction with the solid cellulose;
it is considered the mobile phase. The amino acids will be constantly
equilibrating between being in the mobile organic phase or the stationary
water phase. The more polar the side chain, the more time the amino acid
will spend in the stationary phase. The more hydrophobic the side chain,
the more time it spend in the mobile organic phase. By using a series
of different solvents, all 20 amino acids can be separated in this way.
It works for many other organic molecules as well.
Small PEPTIDES [I emphasize peptides here, oligopeptides, not polypeptides]
can also be separated by both of these techniques; the properties of the
peptides will be a COMPOSITE of the properties of the constituent amino
acids. {Q&A}.
One of the most famous examples of the use of these
methods to analyze peptides rather than single amino acids was in the
study of sickle cell disease. Sickle cell disease is caused by an abnormal
hemoglobin protein. Hemoglobin is made up of several components, one of
which is a polypeptide called alpha-globin. The sequence of amino acids
in beta-globin from sickle cell hemoglobin differs from that of normal
alpha-globin. The nature of that difference can be determined by chopping
up the sickle cell alpha-globin into small peptides and then first separating
them along one edge of a filter paper sheet by paper electrophoresis.
The sheet is then turned 90 degrees and subjected to paper chromatography.
The result is a series of spots (after staining to visualize their positions)
representing all the sub-peptides. One peptide migrates differently in
sickle cell globin compared to normal globin. This peptide can then eluted
from the paper and sequenced. Comparison with the normal counterpart shows
that the sickle cell globin carries a single amino acid substitution.
In place of glutamic acid, it has a valine at one position in the peptide.
How could such a small change have such a large effect? The answer lies
in the 3-dimensional shape of proteins, to which we will turn next.
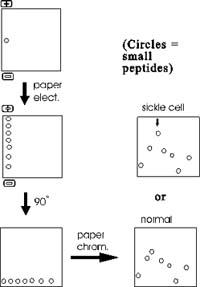
Most proteins can be separated into characteristic
patterns of spots this way. The procedure is called FINGERPRINTING a protein,
since the migration patterns are so characteristic.
Protein 3-dimensional structure
Now let us return to polypeptide structure.
Each polypeptide has a particular sequence of amino acids. Thus if we
could examine several molecules of the protein albumin we might find:
Molecule #1: N-met-leu-ala-asp-val-val-lys-....
Molecule #2: N-met-leu-ala-asp-val-val-lys-...
Molecule #3: N-met-leu-ala-asp-val-val-lys-... etc.
So they have the same primary structure. But as always, we must consider
structure in 3-dimensional space for a real picture of the molecule.
While the linear structure is the same, the 3-d
structure for each molecule must surely be different in solution, no?
After all, thermal motion will be buffeting this rope of strung-together
amino acids all about, so that each molecule will be expected to take
on a random configuration, no? Look at this scale model of a POLYPEPTIDE
OF 500 amino acids, a CLOTHES LINE. The dimensions are about right, but
the side chains have been left out. I have put colored parts of the rope
red to indicate polar side chains, the white
parts being apolar or hydrophobic [board]. At 37 degrees, you might imagine
this clothesline in a Jacuzzi, constantly taking on new shapes, with its
hydrophilic side chains constantly forming new hydrogen bonds to water.
This is the wrong picture. A more appropriate picture is a bundled up
rope, folded into a compact structure that withstands this thermal motion
at body temperatures [bundled rope].. red on outside ...white hydrophobic
on inside (which makes sense based onthe weak bond behavior we discussed).

OK, maybe this molecule could collapse on itself
.. after all the hydrophobic side chains will tend to aggregate. But if
we took another molecule, another linear chain, it would probably fold
a different way, after all, 500 amino acids, there must be many many ways
to get the hydrophobics inside. I could stuff the white parts of the rope
together and put them on the inside in many different ways. But if we
look for a second folded up example of this molecule, it looks like this
[second rope bundle], exactly the same as
the first (note loop count, etc.). Protein molecules exist as precisely
defined 3-dimensional structures in solutions, each molecule like the
next, superimposable.
That is, a typical polypeptide chain, having some 10,000 atoms linked
together, is folded up so that these 10,000 atoms all have the same relative
position in each and every molecule you examine. This still amazes me.
How could this be?
Well, what is holding the molecule in this shape? The four weak bond types
we discussed earlier, plus one new bond to be described in a few minutes.
Let's consider how this folding looks in more detail:
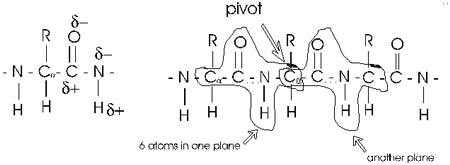
First, the flexible rope was not a good representation of even the backbone,
because the peptide bond itself imposes some constraint on structure.
The peptide bond itself has a property that influences all polypeptides
regardless of the side chains. Because of the electronegativity difference
between C and O or N, there is a partial separation of charge, one you
could have predicted.
What you may not have realized is that the partial + charge on the C and
the partial - charge on the adjacent N, imparts a partial extra bond between
those 2 atoms, and thus a partial double bond character to the C-N bond.
This partial double bond is sufficient to stop free rotation about the
C-N bond. Thus the backbone is not free to rotate around all connections,
but rather each repeat contains 6 atoms confined to one plane:
The polypeptide can be visualized as having a series of planes, each able
to rotate about one another. So a chain would be a better representation
than a rope.
::Secondary (2o)=
alpha-helix, beta sheet::
This partial separation of charge also means that
the O and the NH of the peptide bond can hydrogen bond... to water for
example. Since the NH is a hydrogen donor and the O is a hydrogen acceptor
for a hydrogen bond, we should consider the possibility that these groups
can H-bond to each other. But H-bonds require a linear orientation of
the 3 atoms involved, so certainly the NH of the very next residue cannot
H-bond to a C=O preceding it. But what about the next residue? No, still
can't make it. But by the fifth residue down you are able to line up an
NH to the O: -C=O..H-N-. i.e., there are 3 complete residues 3 in between.
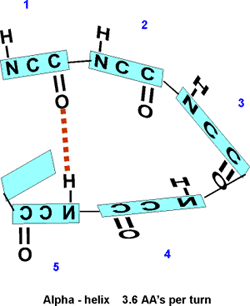

So the C=O of #1 can H-bond to the HN of #5. But then also the C=O of
#2 should be able to H-bond to the HN of #6, and so on. This twisting
and H-bonding can hold the backbone in a HELIX, the so-called alpha-helix.
The alpha-helix is an example of secondary structure,
which is (my definition): structure produced by
regular repeated interactions between atoms of the backbone.
We might expect all the amino acid backbone
atoms to be in an alpha-helical conformation, but we have left out consideration
of the side chains, which can greatly influence the folding, as we will
see in a minute.
The alpha-helix is not the only form of secondary
structure, there is another, the beta-pleated sheet. In this case we once
again have the C=O and the NH of the backbone forming H-bonds to each
other, but in this case two sections of the polypeptide are aligned side
by side:
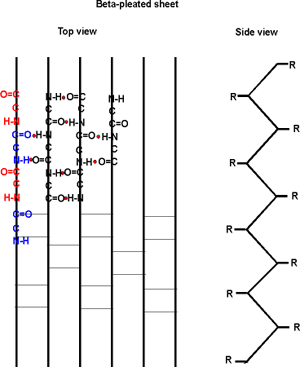
Several sections of polypeptide can line up like this, to produce a sheet
of strands. The chains are usually anti-parallel, but parallel alignments
are also possible. See text for better pictures. B:49 &
[Purves6ed3.5a].
Once
again, side chain interactions play a major role in allowing or disallowing
such secondary structures to form. But in fact, most proteins do have
extensive regions folded into alpha-helices and beta-pleated sheets.
Secondary structure consists mostly of these 2 structures.
Tertiary structure means the overall 3-dimensional
folding of a single polypeptide chain. We will continue with this most
important level of structure next time.
(C) Copyright 2001 Lawrence
Chasin and Deborah Mowshowitz Department of Biological Sciences
Columbia University New York, NY
Clickable pictures are from Purves, et. al., Life, 5th Edition,
Sinauer-Freeman's Images of Life 5.0.
A production of the Columbia
Center for New Media Teaching and Learning