Chapter 6: Correlation, Causation...Confusion and Clarity
[2:] "Smoke and Dust at World Trade Center are Linked to Smaller Babies"
"Belief in Hell Brings Prosperity to Nations"
"Vegetarianism Increases Life Span"
"Premature Babies have Smaller Brains in Youth"
"TV Watching by Toddlers Leads to Attention Deficit Disorder"
"Five Hours of TV a Day Makes Kids Six Times More Likely to Smoke"
[3:] I culled all of these claims from the New York Times in 2003/2004. Some are "common knowledge", some sound plausible, at least one sounds silly. All of these claims are based on one of the most widely misused and misunderstood mathematical operations in existence: correlation analysis. This chapter aims to demystify this relatively simple technique and to provide you with some ground rules for assessing such claims.
[4:] I begin with one of my favorite examples: the correlation between air pollution and premature death. Several decades ago in western Pennsylvania, a study collected the records of both air pollution and deaths due to pulmonary disease from several counties around Pittsburgh when that city was the nation's leading center of steel production. The authors reported a correlation between poor air quality and the death rate. In particular, Allegheny County had the worst air and the greatest number of deaths.
[5:] The conclusion seems obvious: the correlation between air pollution and pulmonary disease implies that air pollution causes deaths. Pollution control laws were just being implemented at the time, yet, as one wag pointed out, there were sites exempted by the County's laws: crematoria. Perhaps, then, the study's authors had their conclusions backwards; really, it is deaths that cause air pollution.
[6:] Several points about this story are worth noting. Although the true relation between air polution and pulmonary disease may seem obvious, a correlation between two varying quantities can never be taken as prima facie evidence that one causes the other. A co-(r)relation is just that: a relationship between two quantities that vary together. It is not a statement about cause and effect. Viewed in isolation, it is not possible to tell what the relationship between two correlated variables is: A could cause B, B could cause A, or a third (or fourth or fifth) factor could cause both A and B.
[7:] I hear you thinking: "Pedant! It's common sense that air pollution causes disease. Why do we need to worry about statistics and uncertainties -- the cause is obvious."
[8:] Here is my cautionary word about common sense. The essayist Philip Slater once wrote: "Humans are unique amongst animals in their practiced ability to know things that are not so." Think about it. How many dogs do you know who believe the stars control their lives? "Oh boy, Mars is in Aries so it's going to be the steak and cheese treats today!" How many monkeys, practiced at dropping coconuts from palm trees, do you suppose believe that heavy coconuts fall faster than light ones? Aristotle and two millenia of his followers steadfastly believed this to be true and wrote hundreds of learned discourses on why it must be so. It's not. Recall Einstein's remark from Chapter 1 on common sense "....that layer of prejudices laid down upon the mind prior to the age of 18." Well, you are 18 now (or almost 18), and it is time to root out and unlearn some of those prejudices. This course will contribute to that process.
CORRELATION DEFINED
[9:] As noted in Chapter 3, scatter plots -- the display of pairs of measurements on a two-dimensional graph -- are a useful tool for finding patterns in data. But as that chapter also made clear, humans are good at finding patterns even when none exist. What we require is an objective, quantitative measure of whether or not the patterns we see are significant. For example, we found in Chapter 3 that the size of a faculty member's office was related to the number of days he or she was out of town -- in the apparently nonsensical sense that the more days faculty are away from campus, the larger their offices. We inferred this relation by looking at a plot with days out of town on the x-axis and size of office in square meters on the y-axis; the points rose more or less steadily from left to right, with one notable outlier point.
[10:] Our goal now is to quantify this apparent effect and determine its significance; i.e., is it a chance effect in our relatively small sample, or an effect for which it is worth searching for a cause? In this case, A clearly does not cause B (inanimate offices can not impel people to leave town), and B does not cause A (outside of Wonderland, structures do not spontaneously change in size owing to their occupants' presence or absence), so we would need to look for some third factor that controls both office size and travel schedules. Is it worth the effort? Is this correlation significant?
[11:] To assess the relationship between pairs of variables, we calculate the
"linear correlation coefficient", often called simply the "correlation
coefficient," which is denoted by the symbol "r." The correlation coefficient is
a quantity, calculable from the data themselves, that signifies how
closely the data points approximate a straight line of the familiar form
y = mx + b. It is defined as follows:
![]()
[12:] where the Σs represent sums over all xi, yi pairs of data points, and <x> and <y> are the mean (average) values of x and y, respectively.
[13:] It is relatively straightforward (although very boring) to show that r can take on any value between +1.0 and -1.0. A value of +1.0 implies a perfect correlation; i.e., the data points all fall precisely on a line defined by the equation for a straight line y=mx+b. The value r=-1.0 means the data are displaying a perfect inverse correlation or anticorrelation -- the slope of the line is negative (i.e., if x gets bigger, y gets smaller and vice versa). If the data have no relationship whatsoever, they are said to be uncorrelated and r=0. Real data usually have some associated uncertainties; as a result, even in the case of a perfect underlying correlation, the results of an experiment will not likely yield an r value of exactly 1 or -1. Likewise, we never expect to find r=0.00 precisely, even if the data have no correlation whatsoever.
CORRELATION APPLIED
[14:] Let's look at the data for faculty office size and time away from campus and calculate the value of r. First we find <x>, the mean office size, and <y>, the average number of days faculty are away from campus, by summing each set of numbers and dividing by 22 (the number of faculty teaching this semester). The results are <x> = 11.6 m2 and <y> = 57.8 days. We then calculate the differences of each point from the mean and sum them (squared or not) as specified in the equation. The result is that r= +0.467, suggestive of a positive correlation.
[15:] Perusal of the office-size/days-away scatter plot immediately shows that one point is anomalous; one faculty member was away nearly 200 days and yet had an average size office. If we delete this point to recalculate, we find r = +0.727, a higher value for the correlation. Is this fair?
[16:] Maybe. But in deciding to ignore any data, one must always proceed with extreme caution. In any experiment, observation or poll of faculty circumstances, it is possible for errors to occur and for unforeseen anomalies to arise. If one has one or two data points that lie far from the rest, it is appropriate to examine them to see if a simple transcription error or experimental breakdown might have occurred. Of course, all of one's data should be thoroughly scrubbed in a similar fashion. In addition to simple errors, it is possible that the experimental design was flawed, leading to one or more anomalous points. In this case, for example, the faculty naturally reported their time away per year based on last year. The one outlying point was from a person who had not yet joined Columbia and happens to have spent most of the year doing field work. We might then justifiably exclude this point by restating the polling criterion to include only faculty teaching at Columbia for the preceding twelve months. In this case, however, we must exclude any other faculty member who did not meet this criterion. It is essential that a scientist be highly disciplined in the matter of data selection (see selection effects in Chapter 7).
[17:] Now that we have a value for r, what do we conclude? Is the trend of office size and days away "significant" in the sense we defined this word in Chapter 5? What is the probability that we would find such a value for r by chance if, in fact, there were no actual relationship between office size and days away? This is clearly a statistical question, and, although it is rather complicated to assess this probability, it can be done, and the results have been collected in a convenient tabular form. Having calculated r for the total number of data points, N, we can simply look up the probability PN(|r| ≥ ro) which is the probability, given N measurements, that we would find an absolute value of r bigger than the listed ro if no real correlation existed. We use the absolute value sign since large values of r can be significant in either the positive or negative sense -- the data could be either highly correlated or highly anticorrelated, with r near 1 or -1.
[18:] A handy reference table is provided here. Using all the data points, N=22.
Looking at the Table shows there are lines for N=20 and N=25 but not 22;
likewise, the values of ro are only listed in intervals of 0.1. We use such
a table by "interpolating" between the listed values. There are elaborate
schemes for interpolation, but for most purposes, a simple linear interpolation
is sufficient. Thus, for our full complement of 22 faculty for which r=0.467, we
look at rows 20 and 25, and columns 0.4 and 0.5. This provides a little square
(or matrix) of numbers
| ro= | 0.4 | 0.5 | |
| N | |||
| 20: | 0.081 | 0.025 | |
| 25: | 0.048 | 0.011 |
[19:] To interpolate the rows linearly, we take the difference between each pair of
numbers, multiply by 2/5 (the fraction of distance between row 20 and
row 25), and then subtract the result from the row 20 value, yielding:
| ro= | 0.4 | 0.5 | |
| N | |||
| 22: | 0.0678 | 0.0194 |
[20:] We can then interpolate in the other direction and find that the probability of obtaining a linear correlation coefficient as large as 0.467 in a sample of 22 data points is 0.0354 or about 3.5%. In other words, once in every 28 times [HUH?] we looked at a dataset of this size, we would find an apparent correlation this good when no relationship whatever existed between the quantities involved.
[21:] Different branches of science have different sociologically defined thresholds for what they consider significant. Most of those branches dealing with people (biology, psychology, neuroscience, etc.) accept 2 sigma or 95% confidence as the level of significance worth taking seriously. With this criterion, we would say that there is a significant correlation between faculty office size and the time spent away from campus, since the probability of obtaining the result we did by chance is only 3.5%. Physical scientists tend to adopt a 3-sigma threshold (99.7% likely, or only a 0.3% probability of chance occurrence). Our result would fail this more stringent test. When we leave out the one discrepant point, however, r = 0.727 for the remaining 21 members of the sample. The table does not even bother to show a value in this location, since the result is significant at more than the 99.9% level and thus would be accepted as meaningful by any good scientist.
[22:] Thus, our analysis has shown that there is a significant positive correlation between faculty office size and amount of time out of town. Note that this statement -- which is all we can fairly draw from our analysis -- provides no information whatsoever on the cause of this relationship. That we must seek through further observation or experimentation.
[23:] Throughout we have been assuming a linear correlation between our two quantities of interest; i.e., that the underlying relationship is best represented by a straight line. This assumption is not valid for all of the physical, biological, or social situations we might encounter. For example, the distance of a stone from the bridge where it is dropped increases with time, so we might say that the distance fallen correlates with time. In this instance, however, the distance (d) increases as time (t) squared: d ∝ t2. If we plot d vs. t, it is apparent that d and t increase together, but a straight line poorly represents the relationship. Likewise, if you were to count the number of yeast cells in a culture dish at hourly intervals, you would see that the number increases with time, but the correct functional relationship is an exponential curve, not a straight line. Methods exist to measure such nonlinear correlations, but I will spare you the details; see this link if you are interested.
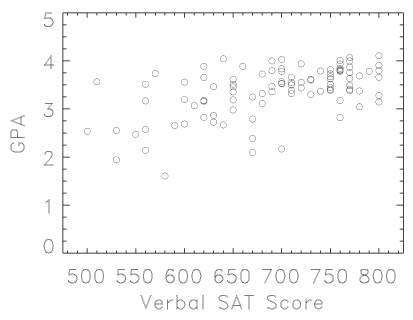
[24:] Here is an example of correlation analysis which you might find more interesting. I have collected anonymous data for 100 randomly selected members of the Columbia class of 2008, which includes Verbal and Math SAT scores plus GPA (grade-point average) at the end of their first year at Columbia. The mean values with their associated statistical uncertainties (quoted as errors in the mean -- see Chapter 5) are as follows: Verbal SAT = 691.5 +/- 7.6, Math SAT 695.7 +/- 6.8, and first-year GPA = 3.374 +/- 0.051. These are consistent with the entire class averages.
[25:] The value for the correlation coefficients are r(verbal-GPA) = 0.547 and r(math-GPA) = 0.436; for N=100, the Table shows both are highly significant. For a sample of this size, a value of r>0.35 will occur by chance less than twice in 1,000 trials; values of ~0.4 and ~0.5 are much less likely still. We can clearly say that the correlation is significant.
[26:] Are you worried? Can I use this result to predict your performance before you even take your first Columbia exam? Should we just grant those of you with high SAT scores your degrees now and save a lot of time and energy?
[27:] Clearly not. The data are plotted here:
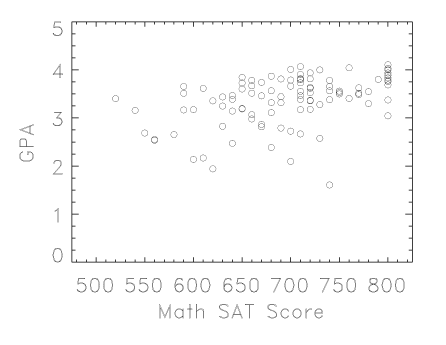
Figure 1: Math SAT vs GPA